Je voulais lancer une newsletter.
J'ai fini par construire
un outil juste pour moi.
J'avais l'idée depuis des mois. Un site où je partagerais ma veille sur l'IA, le business, le sport, tout ce qui m'intéresse. Avant de coder la première ligne, j'ai demandé à Claude Code de faire la recherche marché. Il m'a dit non. Alors j'ai construit autre chose.
L'histoire en trois points
- J'ai voulu lancer une newsletter généraliste. Les sous-agents de recherche m'ont rendu un verdict brutal : marché saturé, coût d'opportunité énorme, moins de 5 % de chances d'en vivre en 24 mois.
- J'ai pivoté quatre fois avant de trancher. Le dernier pivot : arrêter de viser un produit public, construire l'outil de veille dont j'avais besoin pour moi-même.
- En une journée de construction avec Claude Code, j'ai livré un outil qui ingère 96 sources chaque matin à 7h, propose 30 sujets en français, et génère des analyses long-form de 1 000 mots. Tout tourne en local sur mon Mac. Coût réel : environ 5 € par mois.
Tu débutes complet en IA ?
Si certains termes te perdent (Claude Code, terminal, agent, MCP, skill…), commence d'abord par le guide débutant et garde le lexique ouvert dans un autre onglet. Tu reviendras ici avec les bases.
L'idée que j'avais en tête depuis longtemps.
Je voulais lancer un site. Un hub personnel où je partagerais ce que je lis, ce que je regarde, ce que je teste. Pas seulement sur l'IA : aussi sur le business, le sport, la paternité, la géopolitique. L'envie était là depuis des mois. Je me disais qu'à force d'accumuler de la veille, j'avais quelque chose à transmettre.
Avant de coder la première ligne, j'ai fait ce que je fais toujours maintenant : j'ai demandé à Claude Code de vérifier si l'idée tenait la route. Je n'avais pas envie de passer six mois sur un projet pour découvrir en route qu'il n'y avait pas de public. Cette logique de faire travailler des agents en parallèle avant de coder, je l'ai apprise en lisant les travaux de Karpathy.
Ce que les sous-agents m'ont répondu.
J'ai lancé trois sous-agents de recherche en parallèle (des mini-IA spécialisées qui travaillent en parallèle de la conversation principale). Leur mission : fouiller le marché des newsletters et des "second brain publics" en français, chiffrer le potentiel, benchmarker les acteurs existants.
Verdict brutal, que je ne voyais pas venir :
- Le format existe déjà. À l'international, il est saturé.
- La médiane d'une newsletter Substack fait 4 000 € par an après 24 mois de travail.
- Le taux de conversion free vers payant tourne autour de 1 à 3 %.
- Pour sortir du lot, il faut compter 8 à 14 heures par semaine pendant un an et demi, minimum.
- Et surtout : moins de 5 % de chances de dépasser les 4 000 € par an. Un coût d'opportunité énorme face à un temps investi ailleurs.
Les sous-agents ont été très directs : « Laisse tomber la newsletter généraliste multi-sujets. Mets ces heures dans autre chose. »
Les quatre pivots avant de trancher.
Au lieu d'abandonner, j'ai essayé de trouver l'angle qui pourrait marcher. J'ai exploré quatre pistes successives avec Claude Code :
| # | Angle | Verdict |
|---|---|---|
| 1 | Un site généraliste « un fondateur lit le monde » | Nécessite dix ans de track record public que je n'ai pas encore |
| 2 | Une newsletter de curation pure | Déjà occupé par des acteurs français installés (Snowball, Flint, Marie Dollé) |
| 3 | Un carnet de père entrepreneur | Case éditoriale vide, mais demande faible (moins de 5 000 abonnés atteignables) |
| 4 | Du « build in public » multi-projets | Bon fit avec mon profil, mais expose trop mes sociétés |
À la fin de cette exploration, j'étais coincé. Chaque angle avait un défaut bloquant. J'étais prêt à poser le projet dans un tiroir.
Le moment où j'ai changé d'objectif.
Le déclic, c'est quand j'ai arrêté de vouloir un produit et que je me suis demandé ce que moi, concrètement, j'aurais aimé avoir dans ma journée.
Voici ce que j'ai écrit à Claude Code, ce matin-là :
« Ce sera d'abord ma veille à moi. Créer un outil pour faire ma veille sur tous les sujets. Pouvoir ajouter des sources. Le but : avoir la data dont j'ai besoin. »
Tout a changé avec cette phrase. On est passés d'un produit public à vendre à un outil privé à construire. Les contraintes sont tombées une par une :
- Pas besoin de trouver un angle marketing
- Pas besoin d'une promesse vendable
- Pas besoin de 8 à 14 heures par semaine à publier
- Pas besoin d'une stratégie d'acquisition
Juste un outil. Pour moi. Qui tourne chez moi.
Ce que j'ai construit en une journée.
Le 16 avril 2026, en une journée de construction avec Claude Code, j'ai livré la v1 complète de l'outil. Dix phases, de la base de données aux analyses générées, en passant par l'ingestion automatique.
Voici ce qu'il y a dedans :
- 96 sources Business IA multilingues, en anglais, français, espagnol, allemand et japonais — Ethan Mollick, Stratechery, a16z, McKinsey, des podcasts, des chaînes YouTube, GitHub, Hacker News, Reddit, Product Hunt.
- Un worker qui tourne à 7h du matin (un petit programme qui s'exécute tout seul en tâche de fond), déclenché par le planificateur de mon Mac. Il ingère toutes les nouveautés de la nuit pendant que je dors. C'est le même pattern de boucle que je décris dans les loops Claude Code — un agent qui tourne sans surveillance pour produire un livrable au réveil.
- Une base SQLite (une mini-base de données stockée dans un seul fichier) qui vit entièrement sur mon disque. Aucun cloud. Un seul fichier portable.
- Un moteur de recherche sémantique qui tourne en local grâce à Ollama — un modèle d'embeddings multilingue (en clair : qui transforme les textes en chiffres pour comparer leur sens, pas seulement les mots) qui comprend les 96 sources même quand elles parlent des langues différentes. Si l'open source te paraît un sujet de dev, il l'est de moins en moins — Ollama et SQLite sont accessibles sans bagage technique.
- Deux modèles Claude utilisés à des étapes différentes : Claude Sonnet pour proposer 30 sujets du jour, Claude Opus pour rédiger les analyses long-form quand je sélectionne un sujet.
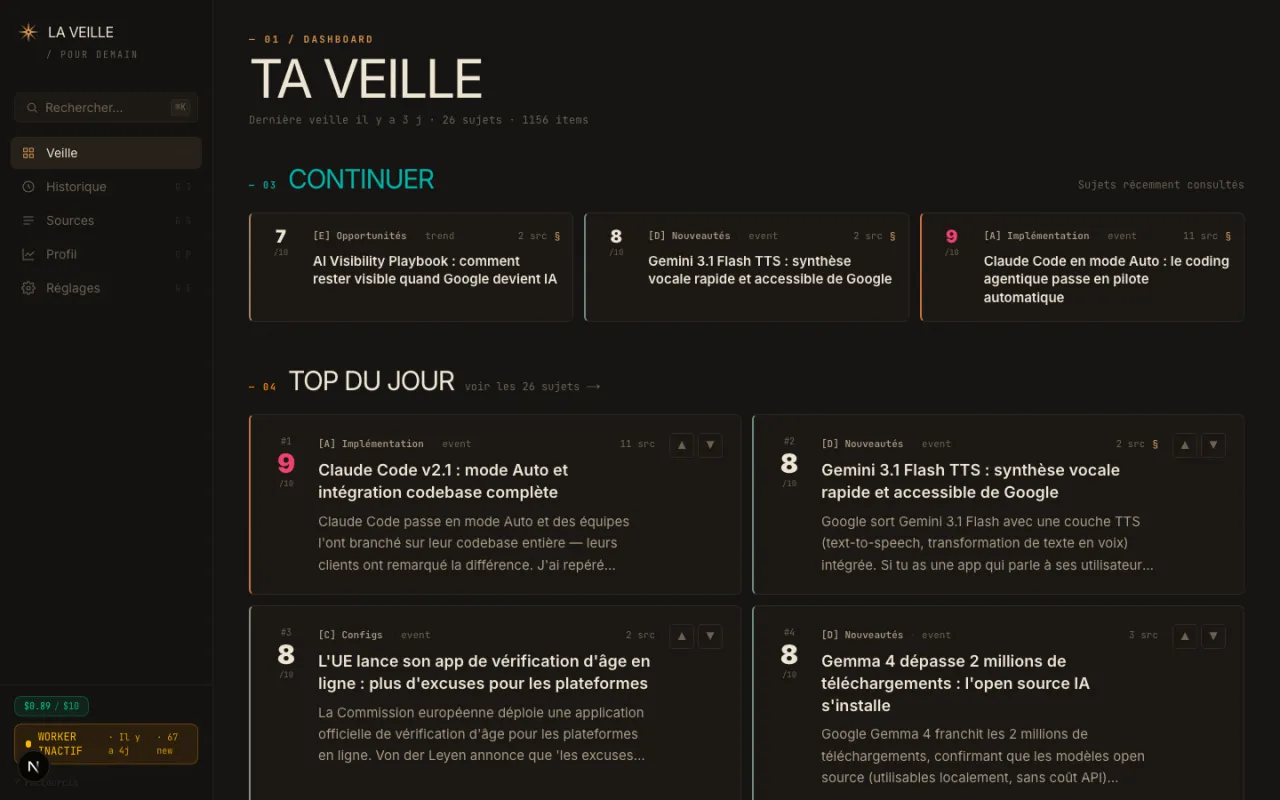
Le tout, en une journée de conception et d'écriture de code. Avec Claude Code. Si tu veux comprendre la philosophie du « second cerveau » qui sous-tend ce genre d'outil, j'ai longuement écrit sur le LLM Wiki de Karpathy qui est une des grandes inspirations de cette approche.
Comment ça marche, étape par étape.
Quand je dis « l'outil ingère 96 sources et me sort 30 sujets », ça reste vague. Voici ce qui se passe vraiment, en cinq étapes, chaque matin pendant que je dors. À la fin de la dernière étape, j'ai dans mon dashboard les sujets sur lesquels je vais passer ma journée.
Le schéma global, en une ligne :
Reddit + HN + GitHub + RSS + YouTube → Bot → Score 5 axes → Top 60 → Mes mains → 10 retenusEt le détail des cinq étapes, avec les chiffres réels d'un run typique du vendredi matin :
1. Collecte parallèle des sources — ~476 items récupérés
Le worker lance en parallèle une trentaine de requêtes : 11 subreddits Reddit, 5 recherches Hacker News, 2 recherches GitHub, 8 flux RSS officiels (OpenAI, Google AI, Hugging Face, Simon Willison, TechCrunch AI, The Verge AI, MIT Tech Review, HN Best), une dizaine de flux Google News dynamiques sur des mots-clés que je veux suivre, et 16 chaînes YouTube via leur flux Atom (gratuit, sans clé API).
Tout ça en parallèle pour ne pas attendre. En 30 à 60 secondes, j'ai environ 476 items bruts dans un tableau en mémoire. Beaucoup sont des doublons, beaucoup sont du bruit. Mais c'est le filet large qu'il faut commencer par lancer.
2. Déduplication par similarité de titre — ~310 clusters restants
Quand OpenAI annonce un nouveau modèle, j'ai la news 5 fois : sur OpenAI Blog, sur HN, sur Reddit r/OpenAI, sur Google News, et sur une vidéo YouTube qui en parle. C'est de l'information utile une seule fois.
L'outil mesure la similarité entre titres (un calcul tout simple qui compare les mots en commun, ce qu'on appelle un « Jaccard ») et regroupe tout ce qui dépasse 50 % de ressemblance. Les 476 items deviennent environ 310 clusters. L'engagement total se cumule au sein du cluster, donc une news vue partout monte mécaniquement.
3. Scoring sur 5 axes — note de 0 à 10 par item
Chaque cluster passe un examen sur cinq critères : combien de gens en parlent, est-ce dans mes sujets, est-ce que ça vieillit bien, est-ce que je l'ai testé moi-même, est-ce qu'il manque déjà un article clair là-dessus. Détail dans la section juste après — j'y consacre un bloc entier parce que c'est le cœur du système.
Le score final est une moyenne pondérée multipliée par un coefficient lié au cluster éditorial (Claude Code = ×1.25, frontier = ×1.0, hors cluster = ×0.5) et par un boost de chaîne YouTube quand l'item vient d'une chaîne pile dans mon univers (1.0 à 1.15).
4. Filtrage anti-bruit + seuil minimum — ~60 items retenus
Le filtrage est ce qui change tout. J'ai construit deux listes de mots-clés au fil des semaines :
- Liste de bruit (KEYWORDS_NOISE) : memes, drama, doomerisme « we're cooked », jailbreaks, NSFW, questions low-value type « am I the only one ». Tout titre qui contient un de ces mots prend une décote massive.
- Liste signal YouTube (YT_SIGNAL_KEYWORDS) : pour les chaînes business comme Silicon Carne ou Underscore_, je n'accepte que les vidéos dont le titre ou la description contient un mot-clé IA / entrepreneuriat / workflow. Sinon Silicon Carne me remonterait des épisodes sur le rap français, ce qui est top mais pas le sujet du jour.
Après le filtre + un seuil minimum de score (5 si l'item est dans un cluster, 7 sinon), il reste environ 60 items qualifiés.
5. Tri final + arbitrage humain — top 15 dans le backlog, 10 retenus à la main
Le top 15 est écrit dans BACKLOG.md avec, pour chaque idée, le score, le cluster, les sources cliquables et un emplacement pour mon angle perso. Les idées vieilles de plus de 60 jours sans être choisies passent automatiquement en « rejetées ». Le backlog actif ne dépasse jamais 40 entrées, ce qui m'évite la paralysie du choix.
Le matin, je regarde le top 15. Je passe environ 10 minutes à arbitrer. Je garde une dizaine de sujets que j'ai vraiment envie de creuser, je passe 5 en « chosen », j'en demande à Claude Opus la version long-form. C'est la seule étape vraiment manuelle du pipeline. Et c'est volontaire : c'est là que ma voix et mon angle entrent dans la chaîne.
Les vraies sources scannées chaque jour.
Quand je dis « 96 sources », je veux que tu puisses vérifier. Voici le détail précis de ce que le worker fouille chaque matin, regroupé par famille. Tous les liens marchent.
Reddit — 11 subreddits
| # | Subreddit | Cluster ciblé | Items / jour |
|---|---|---|---|
| 01 | r/ClaudeAI | Claude Code | ~25 |
| 02 | r/ChatGPTCoding | Claude Code + agents | ~25 |
| 03 | r/Cursor | Outils IA | ~25 |
| 04 | r/LocalLLaMA | Frontier | ~25 |
| 05 | r/MachineLearning | Frontier | ~25 |
| 06 | r/artificial | Frontier généraliste | ~25 |
| 07 | r/Entrepreneur | Entrepreneuriat | ~25 |
| 08 | r/SaaS | Entrepreneuriat IA | ~25 |
| 09 | r/ChatGPT | Outils IA | ~25 |
| 10 | r/OpenAI | Outils IA | ~25 |
| 11 | r/singularity | Frontier (filtre renforcé) | ~25 |
Hacker News + GitHub — recherches ciblées
| # | Source | Requête | Items / jour |
|---|---|---|---|
| 12 | HN Algolia | « claude code » | ~30 |
| 13 | HN Algolia | « anthropic » | ~30 |
| 14 | HN Algolia | « ai agent » | ~30 |
| 15 | HN Algolia | « mcp » | ~30 |
| 16 | HN Algolia | « llm tutorial » | ~30 |
| 17 | GitHub Search API | « claude code » | ~15 |
| 18 | GitHub Search API | « mcp server » | ~15 |
Flux RSS officiels — 8 sources
| # | Source | Type | Items / jour |
|---|---|---|---|
| 19 | OpenAI Blog | Annonces officielles | ~3 |
| 20 | Google AI Blog | Annonces officielles | ~3 |
| 21 | Hugging Face Blog | Modèles open source | ~5 |
| 22 | Simon Willison | Blog perso de référence | ~10 |
| 23 | TechCrunch AI | Médias tech | ~15 |
| 24 | The Verge AI | Médias tech | ~10 |
| 25 | MIT Tech Review | Médias tech | ~5 |
| 26 | HN Best | Curation HN | ~30 |
S'ajoutent à ça 10 flux Google News dynamiques générés sur les mots-clés que je veux suivre (Claude Code, Anthropic, agents IA, AI skills, plugin Superpowers), en français et en anglais. C'est ce qui me ramène les annonces des médias business avant qu'elles n'arrivent sur les blogs.
YouTube — 16 chaînes scannées via flux Atom
Pour chaque chaîne, le worker récupère le flux Atom (gratuit, pas de clé API), filtre les vidéos de moins de 45 jours, applique le filtre signal IA / business et garde au max 10 vidéos par chaîne. Les chaînes-phares (Underscore_, Silicon Carne, Vision IA, Grand Angle, IA et Stratégie) ont un boost de score de ×1.15 parce que c'est le cœur de mon univers.
| # | Chaîne | Catégorie | Boost |
|---|---|---|---|
| 27 | Silicon Carne | IA & Tech | ×1.15 |
| 28 | IA et Stratégie | IA & Tech | ×1.15 |
| 29 | Vision IA | IA & Tech | ×1.15 |
| 30 | Underscore_ | IA & Tech | ×1.15 |
| 31 | Melvynx | IA & Tech | ×1.10 |
| 32 | Grand Angle | IA & Tech | ×1.10 |
| 33 | Grand Angle Nova | IA & Tech | ×1.10 |
| 34 | Alex Hormozi | Business | ×1.0 |
| 35 | Leila Hormozi | Business | ×1.0 |
| 36 | GaryVee | Business | ×1.0 |
| 37 | Iman Gadzhi | Business | ×1.0 |
| 38 | Grant Cardone | Business | ×1.0 |
| 39 | LEGEND | Business | ×1.0 |
| 40 | Oussama Ammar | Business | ×1.05 |
| 41 | Le Déclic | Business | ×1.0 |
| 42 | Antoine Blanco | Business | ×1.0 |
Le total tourne entre 96 et 110 sources actives selon les semaines (les flux Google News varient selon les mots-clés que je modifie). C'est volontairement borné : au-delà, je m'enterre sous le bruit. En dessous, je rate des choses.
Le scoring 5 axes, démystifié.
Tout l'intérêt du pipeline tient ici. Sans scoring, je remonterais 60 items au hasard. Avec scoring, je remonte les 60 items qui matchent mon angle éditorial à moi. C'est ce qui transforme un agrégateur en outil personnel.
J'ai volontairement renoncé à un LLM pour scorer. Trop cher (×476 items × 4 runs / jour = beaucoup trop), trop opaque (impossible de débugger pourquoi un item est en haut), trop lent. À la place, des règles simples sur le titre. Cinq axes, notés sur 10. Voici ce que chacun mesure.
1. Demande — combien de gens en parlent
C'est l'engagement brut : upvotes Reddit + commentaires × 2, points HN + commentaires × 2, vues YouTube / 100 + likes × 10, stars GitHub + forks × 3. Le tout normalisé sur une échelle de 0 à 10.
Exemple concret. Un post r/ClaudeAI à 2 000 upvotes et 300 commentaires fait un engagement brut de 2 600. Score demande : 10. Un release officiel d'OpenAI sur leur blog démarre à 5 (baseline officielle) et monte si HN le reprend.
2. Pertinence — est-ce dans mon domaine
Le titre passe au tamis d'une liste de mots-clés positifs (claude, agent, mcp, skill, automatisation, prompt, llm, solopreneur…) et d'une liste anti-bruit (memes, drama, doomerisme, jailbreaks). Chaque match positif ajoute 1.5 point, chaque anti-bruit retire 4 points.
Exemple concret. « How I built an agent with Claude Code MCP » → +1.5 (built) +1.5 (agent) +1.5 (claude code) +1.5 (mcp) = 9 sur 10. « Anyone else feel AGI is coming? » → -4 (anyone else) -4 (agi coming) = 0 sur 10, éliminé.
3. Evergreen — ça vaut encore dans 6 mois ?
Même logique sur le titre : les mots de tutoriel boostent (« how to », « tutorial », « guide », « pattern », « lessons learned », « ma config »), les mots d'annonce décotent (« released », « announce », « new version », « coming soon »).
Exemple concret. « Lessons learned building 10 Claude Code agents » → +1.5 = 6.5/10, durera dans le temps. « Anthropic announces Claude 5 » → -1.5 = 3.5/10, sera périmé dans 3 semaines (mais peut quand même passer le seuil grâce aux autres axes).
4. Vécu — est-ce que je l'ai testé moi-même ?
Cet axe est neutre par défaut (5/10). Je l'ajuste à la main quand je rentre l'idée dans le backlog. Si j'ai déjà passé une journée sur le sujet, je le monte à 9. Si c'est un sujet dont j'ai juste entendu parler, je le laisse à 5. Si c'est un sujet où je n'ai aucune expérience à apporter, je le baisse à 2.
Pourquoi cet axe existe. Mes meilleurs articles sont ceux où j'ai du vécu réel. Ce filtre m'empêche de me laisser embarquer par des sujets vendeurs sur lesquels je n'ai rien à dire de spécifique.
5. Gap — manque-t-il un article clair sur le sujet ?
L'outil compare le titre proposé à tous les articles déjà publiés sur le site (mesure de Jaccard sur les mots du titre). Plus la similarité est faible, plus le gap est élevé. Si j'ai déjà publié « Les loops Claude Code expliqués », un nouvel item « Understanding Claude Code loops » fait 0.6 de similarité et tombe à 1/10. Si rien ne matche, score 10.
Pourquoi cet axe est crucial. Sans lui, je ré-écrirais 5 fois le même article sur les sous-agents. Le gap me force à explorer des sujets vraiment nouveaux pour ma collection.
La formule finale
La note du titre est une moyenne pondérée :
note_base = (demande × 0.25) + (pertinence × 0.30) + (evergreen × 0.15) + (vécu × 0.10) + (gap × 0.20)
note_finale = note_base × multiplicateur_cluster × boost_chaîne_youtubeLes 6 clusters éditoriaux avec leur multiplicateur :
| # | Cluster | Multiplicateur | Mots-clés type |
|---|---|---|---|
| 01 | Claude Code tutos | ×1.25 | claude code, mcp, skill, hook, sous-agent |
| 02 | Agents IA concrets | ×1.25 | built an agent, gmail agent, n8n, langgraph |
| 03 | Opinions tranchées | ×1.10 | vs, overrated, i tried, lessons learned |
| 04 | Outils IA du moment | ×1.10 | chatgpt, gemini, cursor, perplexity, comparatif |
| 05 | Entrepreneuriat + IA | ×1.0 | solopreneur, mrr, my saas, indiehacker |
| 06 | Frontier vulgarisé | ×1.0 | karpathy, paper, transformer, scaling laws |
| — | Hors cluster | ×0.5 | (décote massive si rien ne matche) |
Et pour les items qui viennent de YouTube, un boost supplémentaire de chaîne (1.0 à 1.15) selon ma proximité avec la voix de la chaîne. Underscore_ qui sort une vidéo Claude Code à ×1.15 + cluster Claude Code à ×1.25 = score gonflé de +44 % vs la valeur brute. Volontaire.
Cette formule a évolué. Au début, j'avais juste l'engagement brut. Le résultat : du drama Reddit en haut, des sujets intéressants en bas. J'ai ajouté la pertinence. Mieux, mais trop de news fraîches sans intérêt pour moi. J'ai ajouté l'evergreen et le cluster. Là j'ai commencé à avoir des idées vraiment pertinentes. Le gap est arrivé en dernier, parce que j'ai écrit deux fois le même article.
Tu veux faire pareil ? Trois niveaux.
L'outil que je décris ici n'est pas magique et il n'est surtout pas le seul chemin. Selon le temps que tu peux y investir, voici les trois niveaux de mise en place. Chaque niveau te ramène 70 à 80 % de la valeur du suivant. Pas besoin d'aller au niveau 3 pour avoir une vraie veille qui change ta journée.
Niveau 1 — Feedly + 5 RSS officiels + checklist papier (5 minutes)
Le minimum vital. Tu crées un compte gratuit sur Feedly, tu y ajoutes 5 flux RSS officiels (OpenAI, Google AI, Hugging Face, Simon Willison, TechCrunch AI). Tu installes l'appli sur ton téléphone. Tu te poses 10 minutes le matin avec un café et tu lis ce qui est remonté.
Ce que tu gagnes. Tu ne rates plus les annonces officielles. Tu arrêtes de scroller X pour découvrir une release que tu pouvais avoir en première main 3 jours avant. Coût : 0 €. Temps de mise en place : 5 minutes. Temps quotidien : 10 à 15 minutes.
La checklist papier en bonus. 3 questions sur un post-it à côté du clavier : (1) « Est-ce que ça touche mon travail ? » (2) « Est-ce que je vais m'en souvenir dans 3 mois ? » (3) « Est-ce que j'ai une raison de partager ça ? ». Si la réponse est non aux trois, tu fermes l'onglet. Ça paraît bête mais ça change tout : tu arrêtes de stocker du bruit.
Quelques sources complémentaires utiles à brancher dès le niveau 1 selon ton angle : Korben.info pour la veille tech française grand public, Console.dev pour les outils dev nouveaux et bien filtrés, et Hacker News directement (ou via son Algolia) pour les conversations qui sortent du circuit officiel.
Niveau 2 — n8n ou Make + scraping Reddit/HN + scoring manuel (1 weekend)
Tu passes au niveau au-dessus quand Feedly ne suffit plus. Tu installes n8n en mode auto-hébergé (gratuit) ou tu prends un compte Make (payant léger). Tu configures un workflow qui fetch Reddit (API gratuite), Hacker News (Algolia API gratuite), tes RSS, et qui te dépose tout ça dans un Google Sheet ou une base Notion chaque matin.
Le scoring se fait à la main : tu mets une colonne « note de 1 à 5 » et tu trie. C'est moins automatique que mon outil mais c'est 10 fois plus puissant que Feedly parce que tu choisis exactement quelles sources rentrent et que tu peux filtrer par mots-clés.
Ce que tu gagnes. Tu vois passer Reddit et HN sans devoir y aller. Tu construis ta propre vue. Coût : 0 à 20 € / mois. Temps de mise en place : un weekend. Temps quotidien : 15 à 20 minutes.
Niveau 3 — Ton propre pipeline Claude Code (1 mois)
C'est ce que j'ai fait. Tu construis le tien avec Claude Code, en repartant de zéro ou en t'inspirant du mien (le code de brainstorm.js est public sur le repo de mon site). Tu obtiens : sources sur mesure, scoring sur mesure, filtres sur mesure, dashboard intégré à ton outil de travail, contrôle total sur tes données.
Ce que tu gagnes. Un outil qui devient une extension de ta tête. Coût : 5 à 10 € / mois en API. Temps de mise en place : 1 mois en fil rouge le soir, ou une journée pleine si tu arrives à libérer un samedi entier comme moi. Temps quotidien : 5 minutes pour arbitrer le top 15.
Honnêtement : commence au niveau 1. Si dans 3 semaines tu te dis « il me manque Reddit et HN », passe au niveau 2. Si dans 3 mois tu te dis « je veux un scoring qui matche pile mes obsessions », passe au niveau 3. La pire erreur, c'est de viser le niveau 3 dès le départ et de ne jamais commencer parce que c'est trop gros à attaquer.
Ma veille avant, ma veille maintenant.
Avant. Je faisais ma veille comme beaucoup : je scrollais sur X, j'allais voir Google News, je traînais sur YouTube. C'était chronophage. Je passais parfois une heure à scroller pour finir avec trois informations en tête, dont deux mal expliquées. Je ratais des annonces importantes parce qu'elles étaient noyées dans le bruit. Et quand je tombais sur une nouveauté intéressante, je n'avais pas le temps de creuser vraiment.
Maintenant. Je me lève, je prends mon café, j'ouvre mon outil. Le worker a déjà digéré les 96 sources de la nuit. Je clique sur « Lancer la veille ». Trente sujets en français apparaissent, classés par score. Je lis les titres, je coche ceux qui m'intéressent. Claude Opus me sort une analyse de 1 000 mots par sujet, en français, avec les sources croisées entre elles.
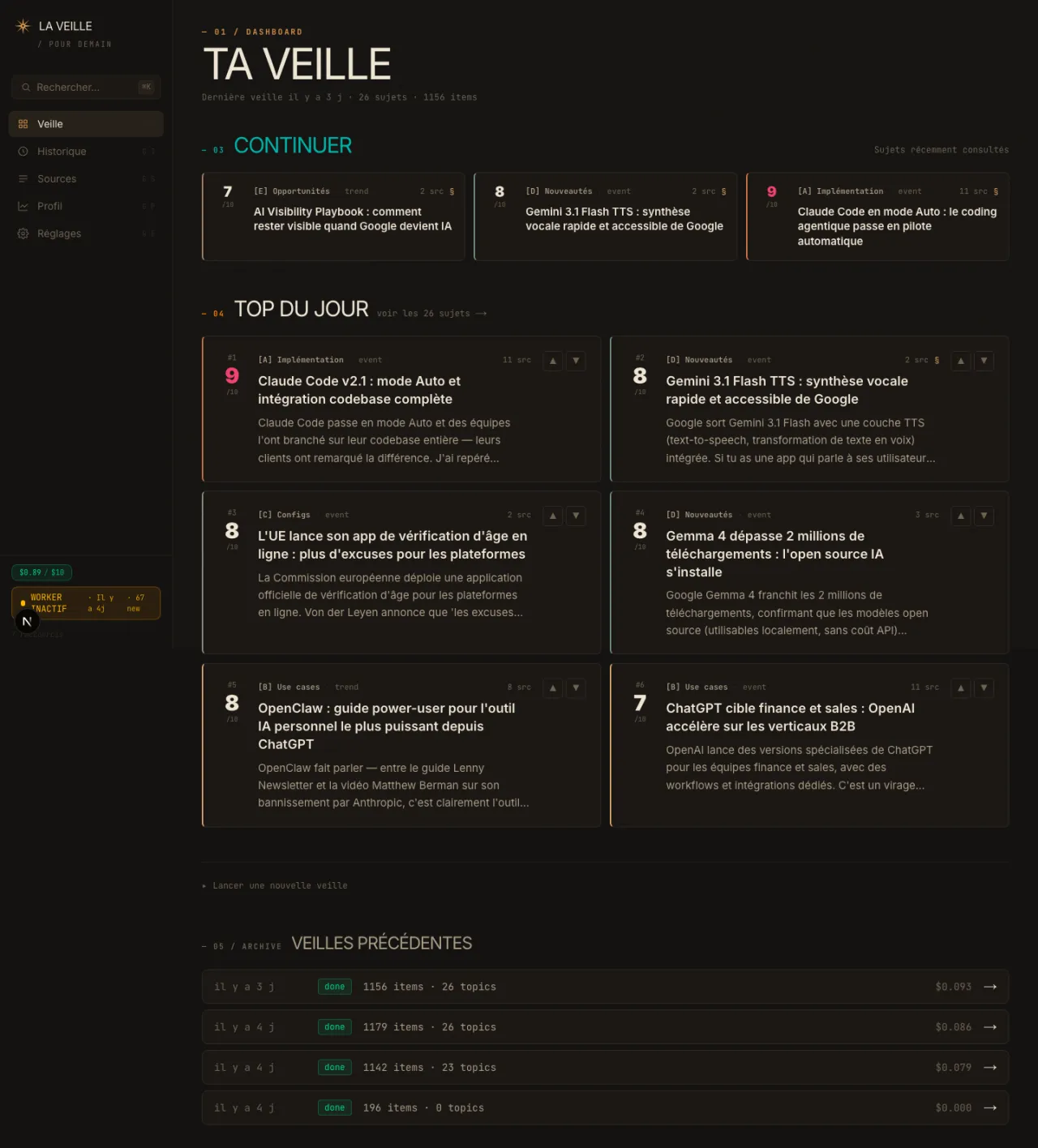
En ce moment, l'outil me fait remonter des sujets précis que je n'aurais pas vus en scrollant :
- Les nouveautés de Gemma, le modèle open-source de Google
- Les annonces d'Anthropic au fil des semaines
- Les analyses de fonds d'investissement américains sur les usages IA en entreprise
Ce sont des sujets que je n'aurais pas trouvés tout seul, ou que je n'aurais pas compris en profondeur si je les avais vus passer sur X.
Ce que ça me coûte, ce que ça me rapporte.
Le coût mensuel tourne autour de 5 € par mois, parfois un peu plus selon ma fréquence d'usage. Max 10 € les mois où je fais beaucoup d'analyses. Ce sont les appels à Claude Sonnet (les 30 sujets proposés chaque jour) et à Claude Opus (les analyses long-form) qui composent presque tout ce montant. Le reste — l'ingestion des 96 sources, les embeddings Ollama, la base SQLite — tourne gratuitement sur mon Mac.
Pour 5 € par mois, voici ce que j'obtiens :
- Ma veille digérée chaque matin
- Des analyses en français sur les sujets que je sélectionne
- La matière pour écrire ma newsletter
- La matière pour produire du contenu (articles, posts, partages)
- Mes données qui restent chez moi, sur mon disque
C'est probablement le meilleur rapport valeur / prix que j'ai obtenu en construisant un outil moi-même.
Ce que je retiens de cette histoire.
Trois leçons, que je me répète depuis :
1. Avant de construire un produit, demande à Claude Code de vérifier le marché.
J'ai failli investir des mois dans une newsletter qui n'avait que 5 % de chances de décoller. Trois sous-agents en deux heures m'ont évité cette erreur. Ce n'est pas une garantie, mais c'est un filtre énorme.
2. L'outil que tu construis pour toi vaut parfois mieux que le produit que tu rêves de vendre.
Je n'ai plus besoin de chercher mille abonnés payants. J'ai besoin d'un outil qui tourne chaque matin. L'un nourrit l'autre, d'ailleurs : la veille que je fais avec cet outil alimente les contenus que je publie. Le produit public est sorti comme une conséquence, pas comme un objectif.
3. En une journée, avec Claude Code, tu peux construire quelque chose qui tourne vraiment.
Pas un prototype. Un outil complet, avec ingestion automatique, clustering, analyses longues, interface soignée. Quand j'étais seul avec mon idée, je me serais dit que c'était un projet de six mois. Avec Claude Code, c'est une journée de construction, et quatre jours plus tard on ajuste la charte graphique pour que ce soit joli.
Et toi, c'est quoi ta veille ?
Si tu fais ta veille comme je la faisais avant — en scrollant X, Google News, YouTube, LinkedIn, avec l'impression de rater l'essentiel — je suis curieux de savoir à quoi ressemble tes journées.
Réponds à cet email avec :
- Les trois sources que tu consultes le plus souvent
- Combien de temps tu passes par jour en veille
- Ce que tu aimerais voir amélioré
Je lis tout. Je ne vends rien. Je cherche juste à comprendre comment les autres s'y prennent.
FAQ pipeline de veille IA.
C'est quoi le scoring 5 axes ?
Cinq axes pondérés : Demande (engagement brut, votes, commentaires), Pertinence (matching avec mes sujets), Evergreen (longévité, pas seulement la news fraîche), Vécu (correspondance avec mes usages) et Gap (sujet rare versus déjà couvert). Le score brut est multiplié par un coefficient cluster (1.0 à 1.25 selon la catégorie éditoriale) et un boost YouTube (1.0 à 1.15 pour les chaînes-phares).
Combien ça coûte par mois ?
Environ 5 € par mois, parfois jusqu'à 10 € les mois où je fais beaucoup d'analyses long-form. Ce sont les appels à Claude Sonnet (les 30 sujets par jour) et à Claude Opus (les analyses) qui composent presque tout. Le reste — ingestion des 96 sources, embeddings Ollama, base SQLite — tourne gratuitement sur mon Mac.
Combien d'idées par run ?
Une run typique : 476 items ingérés depuis 96 sources, 310 clusters après déduplication par similarité Jaccard, 60 items après filtrage signal/bruit, 15 items dans le backlog actif, 10 items que je retiens vraiment pour analyse approfondie. Soit un taux de rétention de 2 % entre l'ingestion brute et ce qui mérite mon attention.
Quelles sources scanne l'outil ?
96 sources en quatre familles. Onze subreddits (r/ClaudeAI, r/ChatGPTCoding, r/LocalLLaMA, r/MachineLearning, r/Entrepreneur, etc.). Sept sources HN + GitHub via Algolia API. Huit flux RSS officiels (OpenAI, Google AI, Hugging Face, Simon Willison, TechCrunch AI, The Verge AI, MIT Tech Review, HN Best). Seize chaînes YouTube via flux Atom. Plus dix flux Google News dynamiques. Total réel : 96 à 110 sources actives selon les semaines.
Faut-il être développeur pour reproduire ce pipeline ?
Non. Pour le niveau 3 (le pipeline complet Claude Code), il faut savoir installer Claude Code, créer un compte Anthropic et accepter une journée pleine ou un mois en fil rouge à construire-tester-ajuster. Mais 70 à 80 % de la valeur s'obtient au niveau 1 (Feedly + 5 RSS officiels, 5 minutes) ou au niveau 2 (n8n auto-hébergé + scraping Reddit/HN, un weekend). Commence au niveau 1, monte si tu en sens le besoin.
Quelle différence entre cet outil et Feedly ?
Feedly est un agrégateur RSS qui te liste les derniers articles publiés. Cet outil va trois crans plus loin : il scrape aussi Reddit, Hacker News et YouTube, il déduplique par similarité Jaccard pour grouper les variantes d'un même sujet, il score sur cinq axes pondérés selon mes obsessions, et il appelle Claude Opus pour produire une analyse française de 1 000 mots par sujet retenu. Feedly te donne du brut, cet outil te donne du digéré et priorisé.
Pourquoi pas un LLM pour scorer plutôt qu'une formule ?
J'ai volontairement renoncé à un LLM pour scorer. Trop cher : sur 476 items par jour, ça ferait des dizaines de milliers d'appels par mois. Trop opaque : impossible de comprendre pourquoi un item bascule vers le haut ou le bas. Trop lent : chaque appel ajoute 2 à 10 secondes, soit des heures de latence sur l'ensemble. La formule mathématique avec multiplicateurs cluster est rapide, lisible et auditable.
Comment ajouter une nouvelle source ?
Trois étapes selon le type. Pour un subreddit ou un RSS officiel : ajoute l'URL dans le tableau de configuration et relance. Pour une chaîne YouTube : résous le channelId une fois (mis en cache 90 jours), ajoute-la au fichier youtube-channels.js avec son boost. Pour une recherche Google News dynamique : ajoute les mots-clés dans le worker. Compte 5 à 15 minutes pour intégrer une source proprement, tester sur un run et ajuster les filtres signal/bruit si besoin.
Pourquoi Ollama plutôt qu'OpenAI embeddings ?
Ollama tourne en local sur mon Mac avec un modèle d'embedding multilingue, gratuitement, sans envoyer une seule ligne sur Internet. OpenAI text-embedding-3-small coûte 0,02 $ par million de tokens — pas cher mais payant, et mes données partent chez OpenAI. Sur 476 items par jour, l'écart financier est minime mais le contrôle des données est total avec Ollama. Et j'évite une dépendance de plus.
Le pipeline marche-t-il sur Windows ?
Oui. Le code est en Node.js + SQLite, deux briques cross-platform. Ollama tourne sur Windows depuis 2024, Claude Code aussi. La seule friction : le worker tourne actuellement sur mon Mac via launchctl pour le déclenchement à heure fixe. Sur Windows il faudrait passer par le Planificateur de tâches Windows ou WSL2. Pour 99 % du code, zéro modification nécessaire.
Tu repères une erreur ?
Une info obsolète, un chiffre qui a bougé, une source périmée ? Écris-moi à sagnier.jeremy@gmail.com · je corrige en 48h max et je note la date de MAJ en haut de l'article. Les retours terrain valent mille fois les articles — je lis tout, je réponds.
On continue ensemble ?
Je teste l'IA pour de vrai et je partage ce qui marche, sans jargon ni hype. Si cet article t'a servi, le plus simple pour ne rien rater c'est ma lettre du vendredi. Et si tu as une question ou un doute : réponds-moi, je lis tout.